
Новая ИИ-модель VSSFlow, разработанная при поддержке Apple, способна генерировать звуки и речь на основе немых видеороликов. Система использует инновационную архитектуру, которая объединяет обе задачи в едином механизме и показывает результаты на уровне лучших существующих аналогов.
Проблема нынешних моделей
Большинство современных систем генерации звука по видео плохо справляются с синтезом речи. Точно так же модели преобразования текста в речь не умеют создавать неречевые звуки, поскольку изначально разрабатывались для другой цели. Кроме того, предыдущие попытки объединить обе задачи строились на предположении, что совместное обучение снижает производительность, что приводило к многоэтапным схемам с раздельным обучением речи и звуковых эффектов — это усложняло весь процесс.
В этой ситуации три исследователя из Apple совместно с шестью специалистами из Народного университета Китая создали VSSFlow — новую ИИ-модель, которая генерирует и звуковые эффекты, и речь из немого видео в рамках единой системы.
Решение через совместное обучение
VSSFlow использует несколько концепций генеративного искусственного интеллекта: преобразует текстовые расшифровки в последовательности фонетических токенов и обучается восстанавливать звук из шума с помощью технологии flow-matching, которая тренирует модель эффективно переходить от случайного шума к целевому сигналу.
Всё это помещено в 10-уровневую архитектуру, которая напрямую встраивает видеосигналы и текстовые расшифровки в процесс генерации аудио, позволяя модели обрабатывать звуковые эффекты и речь в единой системе. Что особенно интересно: исследователи отметили, что совместное обучение на речи и звуках фактически улучшило производительность обеих задач, а не привело к конкуренции или снижению общей эффективности.
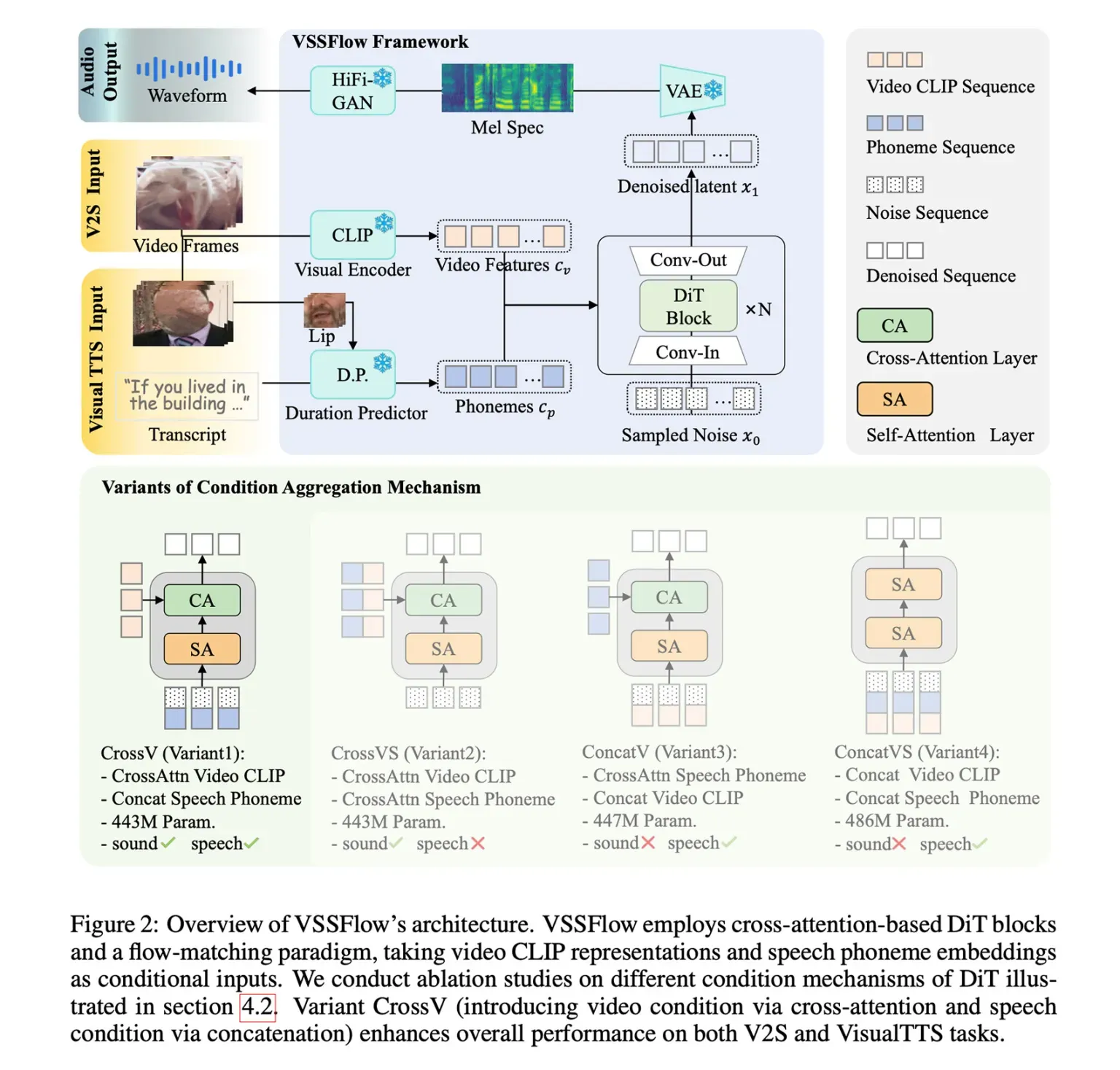
Для тренировки VSSFlow исследователи загрузили в модель микс из немых видео с окружающими звуками (V2S), немых говорящих видео с текстовыми расшифровками (VisualTTS) и данных для синтеза речи (TTS) — это позволило системе одновременно изучать звуковые эффекты и разговорную речь в едином сквозном процессе обучения.
Важно, что в изначальном виде VSSFlow не умела автоматически генерировать фоновый звук и речь одновременно в одном выходном файле. Чтобы добиться этого, исследователи дополнительно дообучили уже натренированную модель на большом наборе синтетических примеров, в которых речь и окружающие звуки были смешаны вместе — так модель научилась понимать, как они должны звучать одновременно.
Как работает VSSFlow
Для генерации звука и речи из немого видео модель начинает со случайного шума и использует визуальные подсказки, взятые из видео с частотой 10 кадров в секунду, чтобы формировать окружающие звуки. Одновременно текстовая расшифровка того, что произносится, даёт точные указания для генерируемого голоса.
При тестировании против узкоспециализированных моделей, созданных только для звуковых эффектов или только для речи, VSSFlow показала конкурентные результаты в обеих задачах и лидировала по нескольким ключевым метрикам, несмотря на использование единой унифицированной системы.
Исследователи опубликовали множество демонстраций звука, речи и совместной генерации (на основе видео Veo3), а также сравнения VSSFlow с несколькими альтернативными моделями. Все демонстрационные материалы доступны на специальной странице проекта.
Ещё одна важная деталь: исследователи выложили код VSSFlow в открытый доступ на GitHub и работают над публикацией весов модели. Кроме того, они готовят и демонстрационную версию.


