
Исследователи Apple совместно с Висконсинским университетом в Мадисоне представили новый метод обучения искусственного интеллекта для генерации описаний к изображениям. Фреймворк, получивший название RubiCap, позволяет создавать более точные и подробные текстовые пояснения, при этом сами нейросети оказались значительно компактнее существующих аналогов.
В чём суть технологии?
Речь идёт о так называемом «плотном описании изображений» (dense image captioning). В отличие от классического подхода, когда нейросеть выдаёт краткую выжимку того, что происходит на картинке в целом, новая технология выделяет множество отдельных элементов и областей. Каждая деталь получает собственное детальное описание, что даёт ИИ гораздо более глубокое понимание сцены.
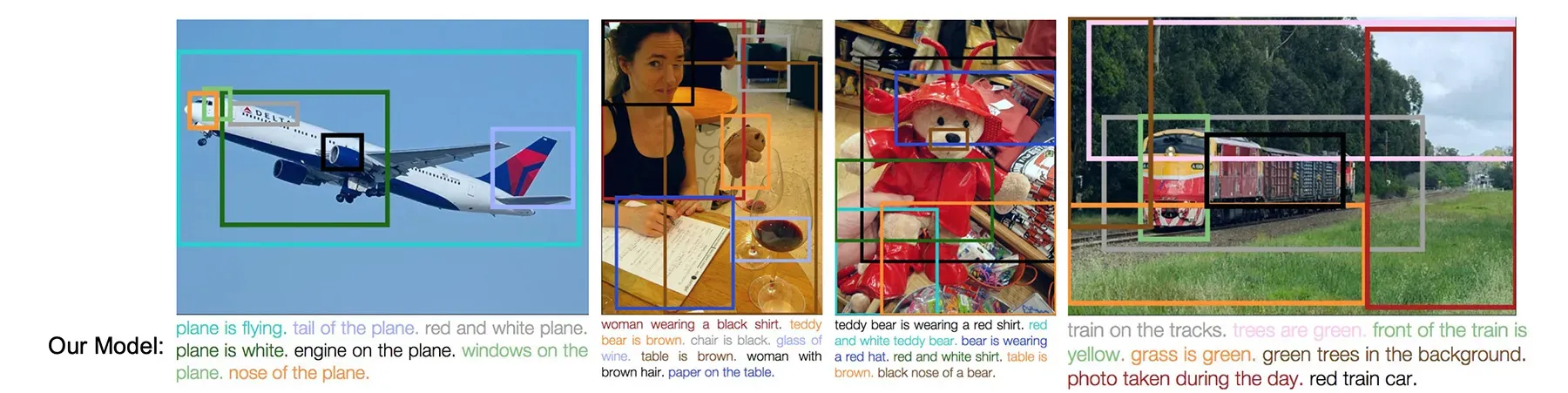
Подобный подход критически важен для предварительного обучения визуально-языковых моделей и генераторов изображений по тексту. На практике такие алгоритмы могут радикально улучшить поиск по картинкам и инструменты универсального доступа для людей с нарушениями зрения.
Как решали проблему?
До сих пор создание подобных систем упиралось в серьёзные ограничения. Привлекать людей-экспертов для разметки данных слишком дорого. Если же использовать другие нейросети для генерации искусственных текстов, результат получается однообразным, а ИИ слабо справляется с новыми задачами. Обучение с подкреплением (RL) могло бы помочь, но обычно оно работает только там, где есть чёткие алгоритмы проверки – непозволительная роскошь для творческих задач вроде описания картинок.
Чтобы обойти эти препятствия, команда применила нестандартный подход. Они взяли 50 тысяч случайных изображений из открытых обучающих баз данных PixMoCap и DenseFusion-4V-100K. Для каждого из них сгенерировали несколько вариантов описания с помощью передовых моделей: Gemini 2.5 Pro, GPT-5, Qwen2.5-VL-72B-Instruct, Gemma-3-27B-IT и других. Параллельно своё собственное описание предлагала и обучаемая модель RubiCap.
Далее в дело снова вступала Gemini 2.5 Pro: она анализировала картинку и все варианты текстов, находила совпадения, ошибки и упущения, после чего формулировала чёткие критерии для оценки. Финальным «судьёй» выступала модель Qwen2.5-7B-Instruct – она выставляла баллы по этим критериям. Благодаря такой многоступенчатой проверке обучаемая нейросеть получала максимально точную и структурированную обратную связь.
Результаты, которые удивляют
В итоге Apple выпустила три версии модели: RubiCap-2B, RubiCap-3B и RubiCap-7B на 2, 3 и 7 миллиардов параметров соответственно.
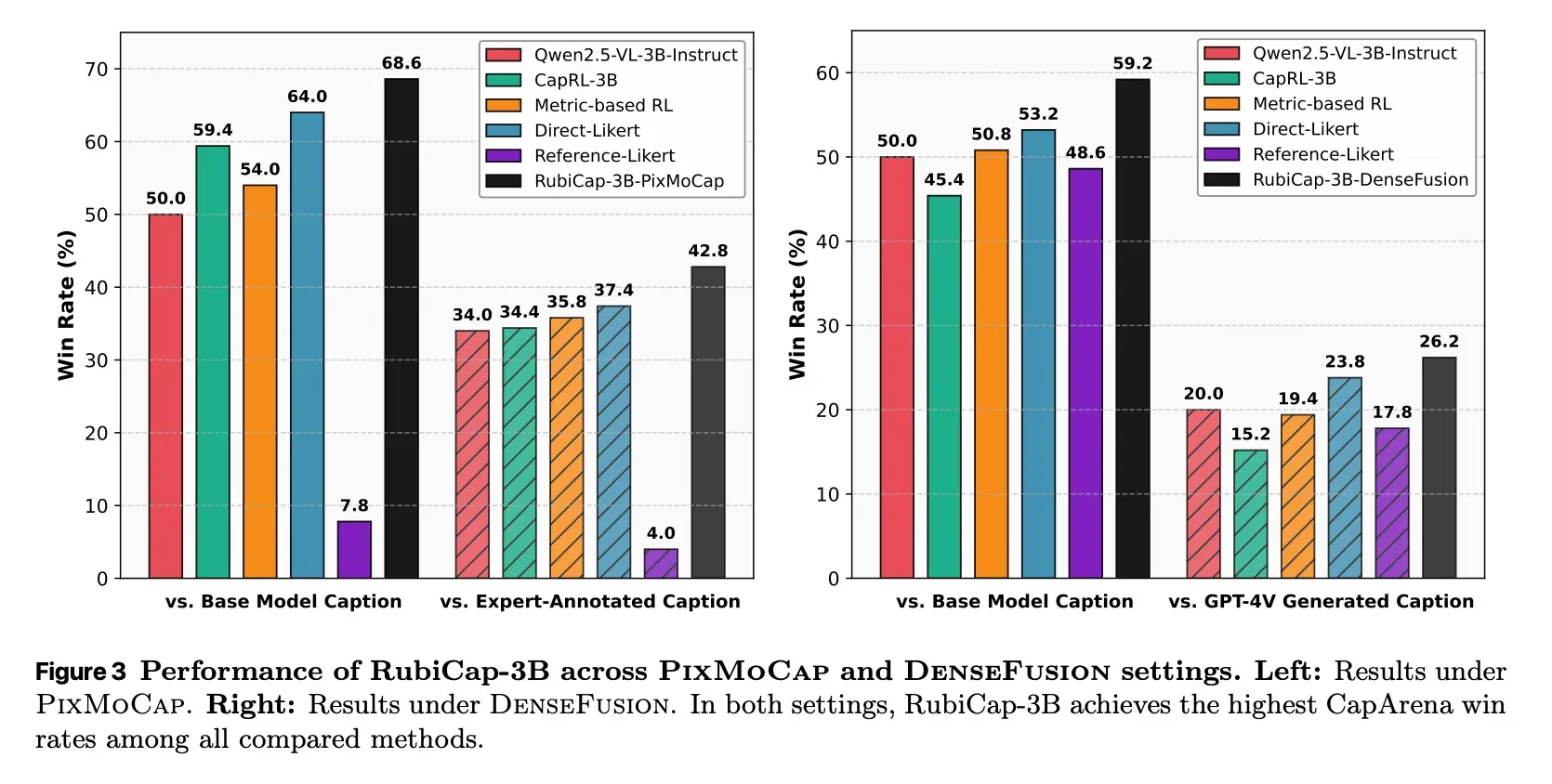
В ходе тестов эти компактные модели продемонстрировали выдающиеся результаты, обойдя конкурентов, чей размер достигает 72 миллиардов параметров. В «слепом» тестировании семимиллиардная версия RubiCap чаще других признавалась лучшей, показав высочайшую точность и минимальное количество «галлюцинаций» (выдуманных фактов).
Примечательно, что в некоторых бенчмарках модель на 3 миллиарда параметров даже превзошла более крупную версию на 7 миллиардов. Это доказывает важный тезис: для глубокого понимания изображений нейросетям вовсе не обязательно наращивать гигантские вычислительные мощности. Компактные и умные алгоритмы могут справляться с задачей эффективнее «тяжеловесов».


