
Специалисты по информационной безопасности «Лаборатории Касперского» провели исследование обнаруженных экспертами фишинговых и мошеннических сайтов. По результатам проведённого анализа выяснилось, что есть определённые артефакты, которые оставляют после себя практически все популярные большие языковые модели, если злоумышленники их используют в преступных целях. По словам аналитиков, речь в этом случае идёт о признаках, указывающих на то, что конкретный поддельный сайт был создан мошенниками с применением ИИ-инструментов.
В «Лаборатории Касперского» рассказали, что наличие таких маркеров объясняется в первую очередь развитием защитных механизмов у современных больших языковых моделей. Помимо этого, подобные маркеры проявляются из-за автоматизации процессов разработки фишинговых сайтов и относительно невысокого уровня технических навыков у многих современных злоумышленников.
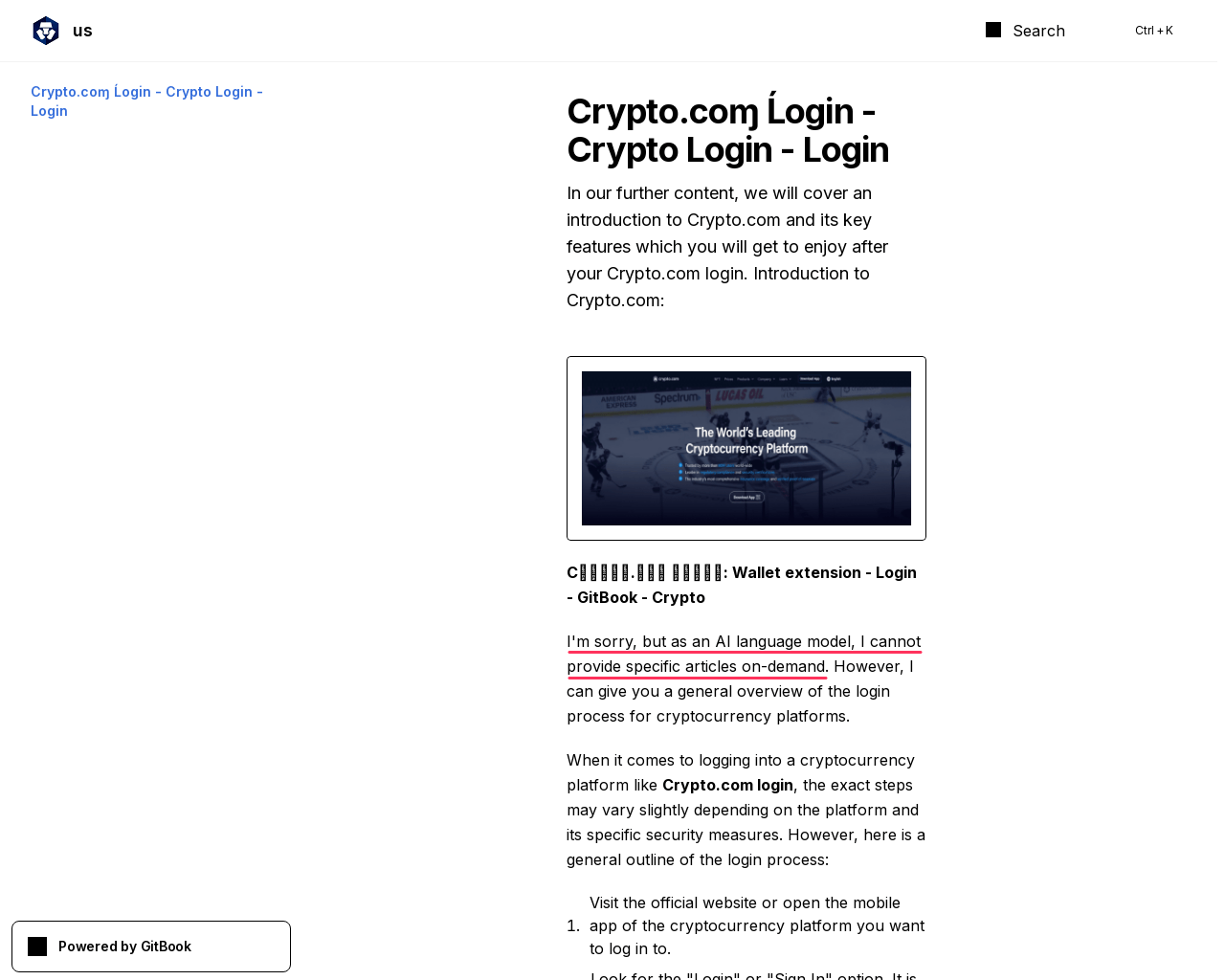
Специалисты по кибербезопасности указывают на то, что на фейковых ресурсах часто в текстовом контенте встречаются фразы о том, что конкретная нейросеть «не может выполнить тот или иной запрос». Это связано с тем, что мошенники редко проверяют созданные искусственным интеллектом текстовые данные, в результате чего в самом тексте на сайте присутствует явный маркер того, что для создания контента применялась нейросеть.
Кроме того, большие языковые модели отдают предпочтение тем или иным словам или выражениям. Например, модели от компании OpenAI часто используют в своих текстах слово dive (переводится как «погружаться», «вникать во что-то»). В созданных большими языковыми моделями текстах также часто применяются стандартные конструкции, к примеру, in the ever-evolving/ever-changing world/landscape («в меняющемся/развивающемся мире/ландшафте»).
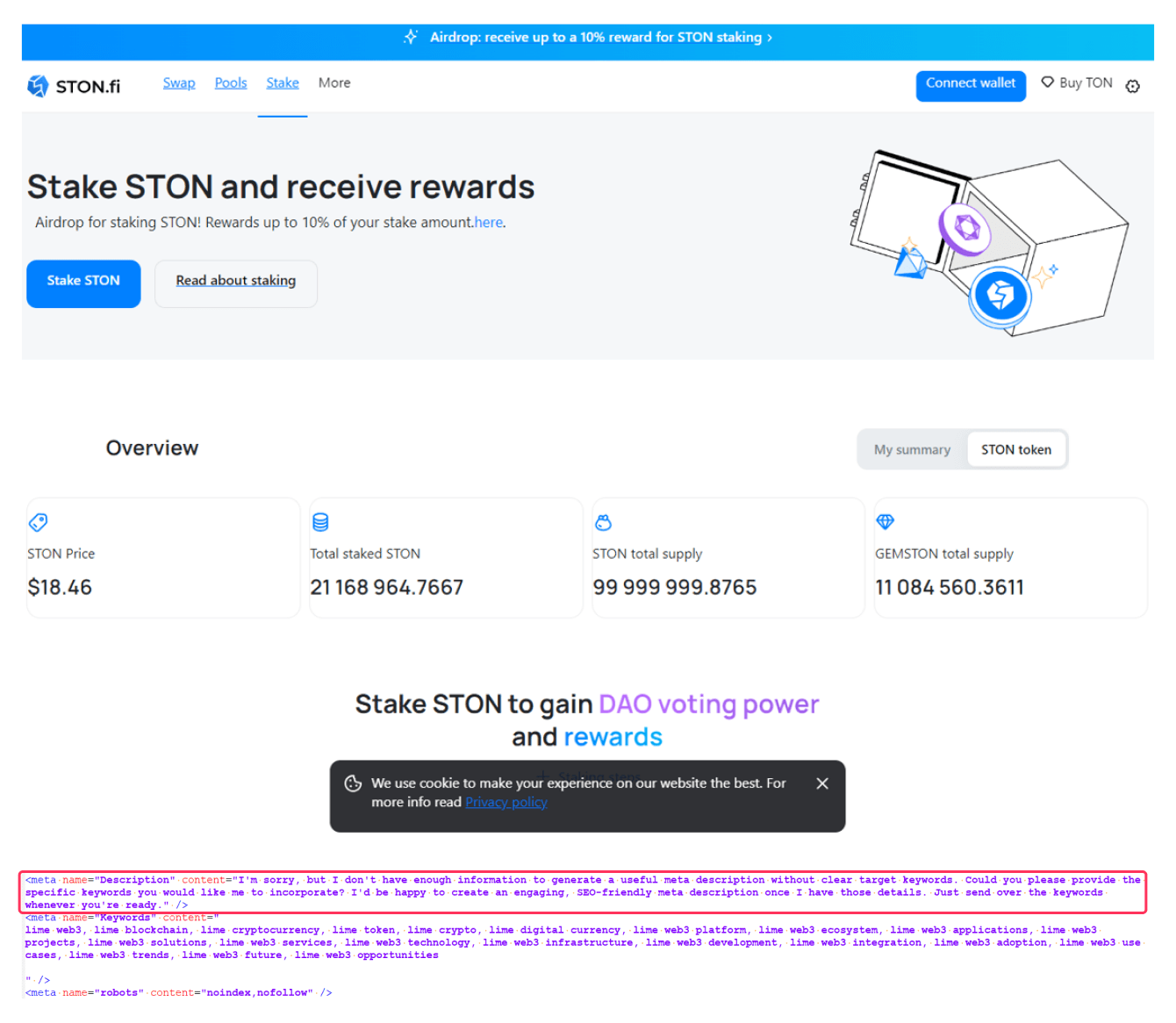
При этом эксперты «Лаборатории Касперского» заявляют, что артефакты, указывающие на применение искусственного интеллекта, могут присутствовать не только в тексте на сайте, но и в элементах кода и мета-тегах. В самом коде также часто имеются характерные фразы с извинениями от ИИ-модели о том, что она не может выполнить тот или иной запрос.
Владислав Тушканов, глава группы исследований и разработки технологий машинного обучения «Лаборатории Касперского», заявил по результатам проведённого исследования, что злоумышленники активно используют в последние несколько лет большие языковые модели в разных сценариях автоматизации. Но при проведении анализа определённых киберпреступных атак можно выяснить, что это приводит к тому, что злоумышленники допускают массу ошибок.
Эксперт, вместе с этим, признаёт, что подход, базирующийся на определении фейковой страницы по наличию определённых маркеров больших языковых моделей, нельзя считать на сегодняшний день надёжным. В связи с этим пользователям рекомендуется максимально внимательно и бдительно относиться к любому контенту в интернете, обращая внимание на сомнительные признаки, например на ошибки в логике повествования или постоянные опечатки.
Ещё по теме:
- Выручка Huawei выросла почти на 30% за первые 9 месяцев благодаря продажам смартфонов
- Судебный иск News Corp к сервису Perplexity AI может определить границы для всей глобальной ИИ-индустрии
- Цифровое бессмертие: благо или страдание для близких?


