
Благодаря использованию программного пакета DrEureka каждый пользователь может начать обучение роботов с применением больших языковых моделей, в том числе и GPT-4. Это программное обеспечение пользуется в своей работе принципиально новым подходом, так называемым «обучением с нуля», в процессе которого модель искусственного интеллекта первоначально обучают сложным навыкам исключительно в виртуальной среде, предоставляя ей необходимые подсказки, и только после этого переходят к выполнению поставленных задач в реальных условиях.
Например, с помощью инструмента DrEureka разработчики смогли научить робота-собаку балансировать и ходить по большому мячу для йоги. При этом обучение происходило только в виртуальной среде. Создатели программного пакета также рассказывают, что их инструмент DrEureka превосходит человека в процессах обучения роботов. Согласно статистике, скорость обучения в этом случае увеличивается на 34%.
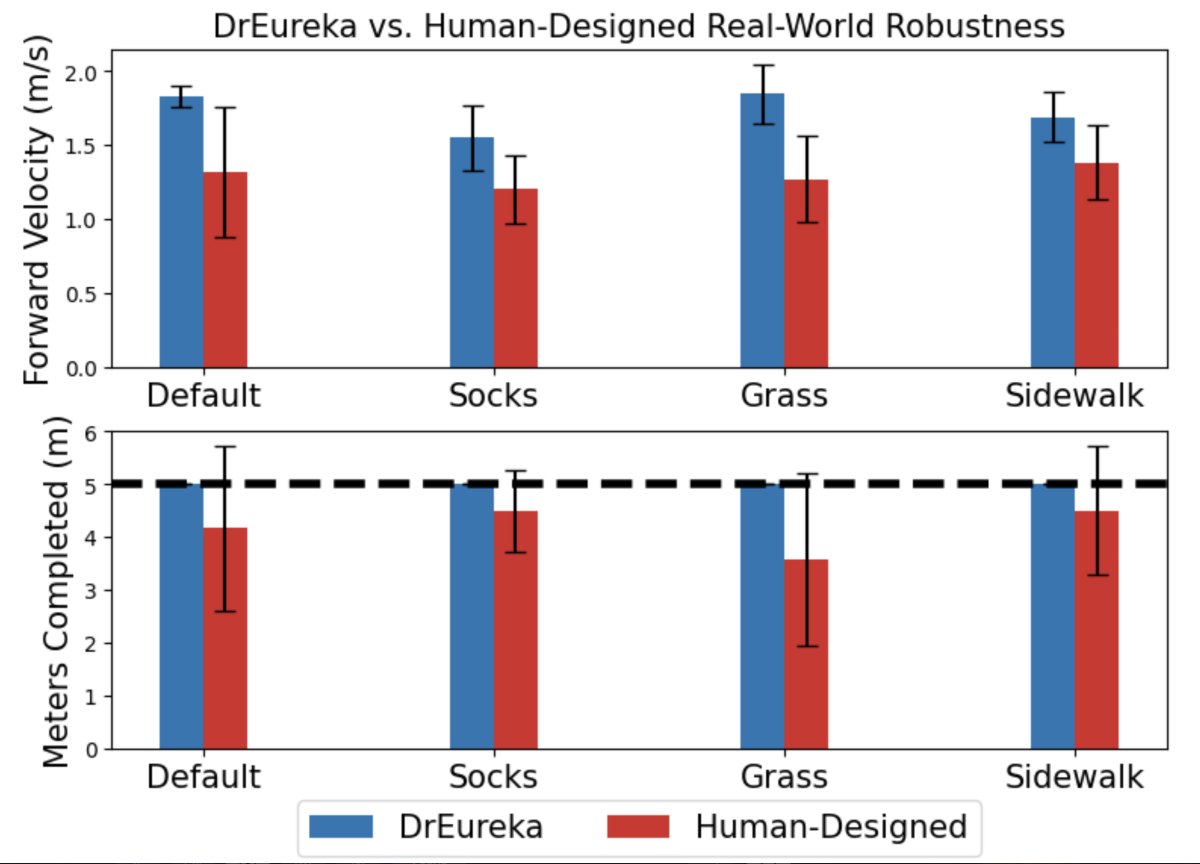
DrEureka представляет собой новый открытый программный пакет, доступный всем пользователям. С его помощью можно тренировать роботов для выполнения различных задач с помощью искусственного интеллекта. Обучение роботов происходит в виртуальной среде, но с моделируемой физикой, поэтому там можно выполнять различные задачи и тренироваться перед тем, как делать что-то в реальных условиях.
Энтузиаст Джим Фан, разработчик инструмента, наглядно продемонстрировал эффективность своего программного обеспечения. С его помощью робот-собака Unitree Go1 обучался балансировать на мяче для йоги в виртуальной среде, где создавались различные параметры для тренировок: центр тяжести, демпфирование массы, трение и многие другие. При этом в ходе такого образовательного процесса роботу поступали различные подсказки от большой языковой модели GPT-4. По словам создателя, искусственный интеллект также имеет возможность самостоятельно написать код, формирующий систему вознаграждений и штрафов для обучения роботов в цифровой среде, где 0 будет означать провал, а любое значение выше 0 — успех.
С помощью такой системы, как рассказывают разработчики, можно сформировать параметры, сводя к минимуму или увеличивая до максимума точки отказа или сбоя робота в разных областях. Искусственный интеллект самостоятельно может подобрать оптимальную упругость мяча, мощность двигателя робота, уровень свободных действий конечностей и демпфирование. После каждого цикла симуляции искусственный интеллект проводит анализ, насколько хорошо робот справился с заданием, и как можно улучшить выполнение различных действий.
Ещё по теме:
- Руководитель отдела маркетинга Apple TV+ Рики Штраус уходит из компании
- По предложению Владимира Путина в России будут разработаны механизмы контроля за рынком компьютерных игр
- К функции «Люди рядом» в Telegram есть большие вопросы в плане конфиденциальности пользователей


