
Компания Perplexity анонсировала новый подход к обеспечению безопасности ИИ-агентов, работающих в интернете. Её система BrowseSafe создана специально для защиты от атак типа prompt injection — приёмов, когда вредоносные инструкции маскируются под обычное содержимое веб-страниц.
По утверждению разработчиков, новый инструмент способен блокировать до 91% угроз, при этом обеспечивая скорость реакции менее полсекунды. Это серьёзный шаг вперёд по сравнению с предыдущими решениями, задержки в которых варьировались от 2 до 20 секунд.
Тема приобрела актуальность после обнаружения серьёзной уязвимости в августе 2025 года. Браузер Comet, разработанный самой Perplexity, стал объектом внимания специалистов из Brave.
В отчёте говорилось, что ИИ-агенты, встроенные в Comet, имеют доступ к авторизованным сессиям пользователя, в т. ч. почту, банковские аккаунты и корпоративные ресурсы. Это превратило их в потенциальную мишень для атак, при которых вредоносные команды внедрялись прямо в текст или структуру страницы. Например, через невидимые HTML-комментарии злоумышленники могли выманивать личные данные и коды подтверждения.
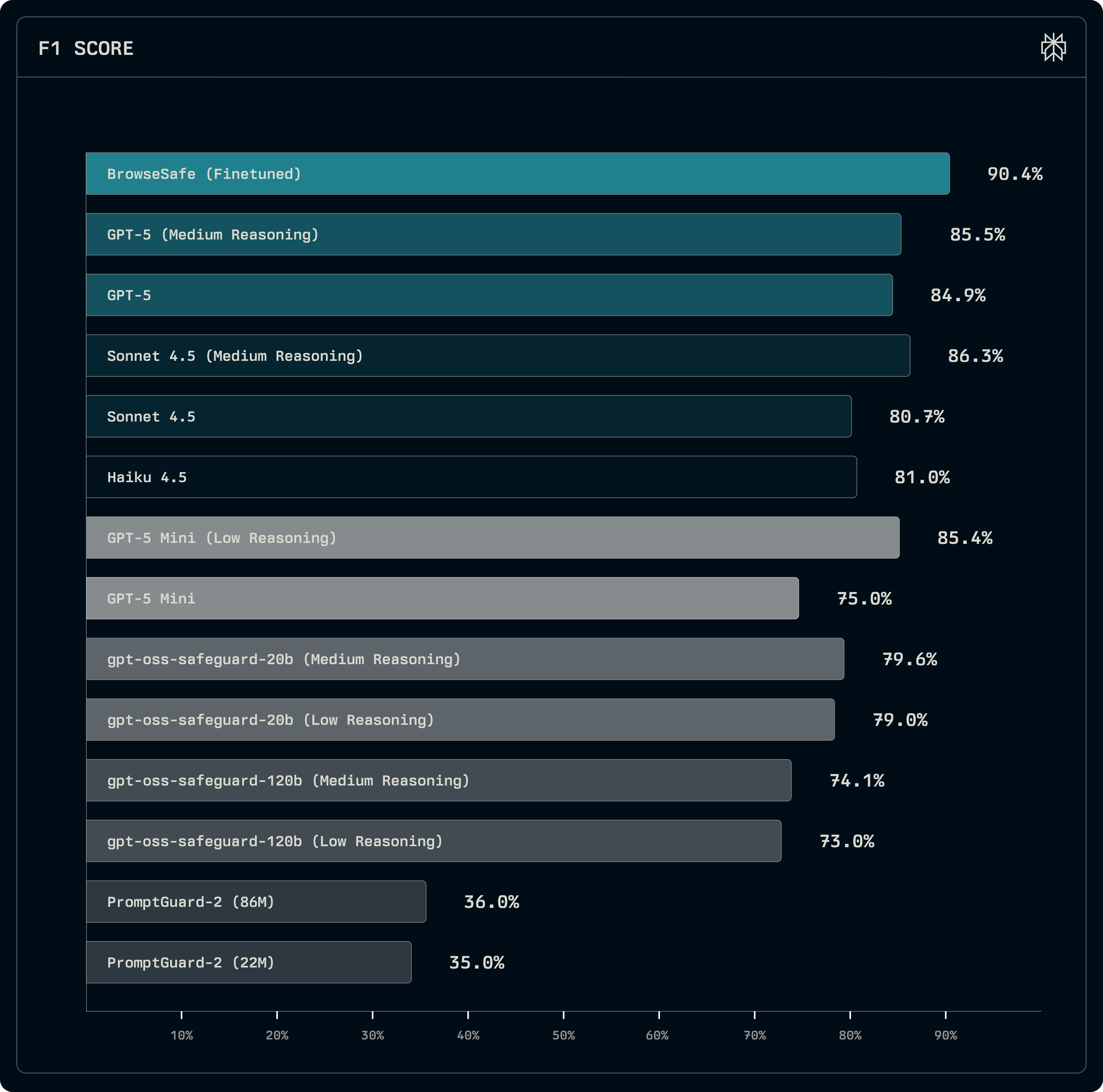
По заявлению Perplexity, большинство существующих систем, даже продвинутые модели уровня GPT-5, обеспечивают защиту лишь на уровне 85%. Другие решения, вроде PromptGuard-2, фиксируют около 35% инъекций. BrowseSafe показывает более высокие результаты, что обусловлено как архитектурными особенностями, так и переосмыслением принципов тестирования.
Для получения точных и репрезентативных данных компания создала собственный набор тестов BrowseSafe Bench. В отличие от упрощённых бенчмарков, вроде AgentDojo, этот пакет делит угрозы по типу, способу внедрения и языковой структуре.
Среди сценариев — как прямые команды, так и грамотно завуалированные фразы, способные обмануть даже продвинутые модели. В тестах используются и безвредные элементы, намеренно напоминающие вредоносные, чтобы избежать переобучения и ложных срабатываний.
BrowseSafe работает на базе модифицированной версии модели Qwen3-30B-A3B-Instruct-2507, адаптированной для многозадачной обработки. Система реализует трёхуровневую защиту: начальный фильтр быстро оценивает контент, подозрительные случаи передаются в более сложную модель с поддержкой логических цепочек, а оставшиеся — на дальнейшее обучение. Такая структура позволяет обеспечивать защиту в реальном времени без ощутимых задержек для пользователя.
Тестирование выявило интересные зависимости. Атаки на нескольких языках снижают точность детекции до 76%, а внедрение команд в открытом тексте оказывается эффективнее, чем в комментариях. Кроме того, присутствие нескольких «псевдопромптов» (фрагментов, похожих на команды, но не содержащих угроз) сбивает модель с толку, что говорит о высокой чувствительности алгоритма к формальным признакам.
Разработчики отмечают, что текущий уровень защиты, несмотря на успехи, не является финальным. Около 9-10% вредоносных инструкций по-прежнему остаются незамеченными, особенно если они маскируются под нестандартные форматы — стихи, неструктурированные записи, сообщения на редких языках. Это формирует дополнительную зону риска в условиях, где ИИ-агенты получают доступ к реальным аккаунтам и конфиденциальной информации.
Ещё по теме:
- Слух: в iPhone 18 Pro Face ID уйдёт под экран, но «остров» останется
- Apple запустила виртуальную академию производства для американских предприятий
- Что произойдёт, когда на калькуляторе 1950-х годов поделить на ноль


