
Исследовательская команда Института искусственного интеллекта AIRI и МФТИ при содействии Центра робототехники Сбера представила AmbiK — открытый набор данных, ориентированный на оценку способности ИИ понимать бытовые указания, сформулированные в нестрогой форме.
Новый бенчмарк стал самым масштабным в своей категории, потому что содержит 2000 ситуаций, в которых робот сталкивается с расплывчатыми, многозначными или неполными инструкциями.
Разработка нацелена на решение проблемы интерпретации повседневных команд, с которыми будущим роботам придётся сталкиваться в домашних условиях.
Примеры вроде «принеси что-нибудь попить» оказываются затруднительными для алгоритмов. В частности, машины не понимают, что утром уместнее предложить чай, а ребёнку не стоит приносить кипяток.
В отличие от человека, робот не ориентируется в предпочтениях семьи, не интерпретирует ситуацию и не способен отличить масло от воды по признаку пригодности к употреблению.
AmbiK создавался как инструмент, позволяющий оценивать не распознавание слов, а способность интерпретировать контекст, учитывать здравый смысл и улавливать границы неопределённости. Каждое задание в датасете сопровождается планом действий, что позволяет определить точку, на которой алгоритм теряет смысловой ориентир.
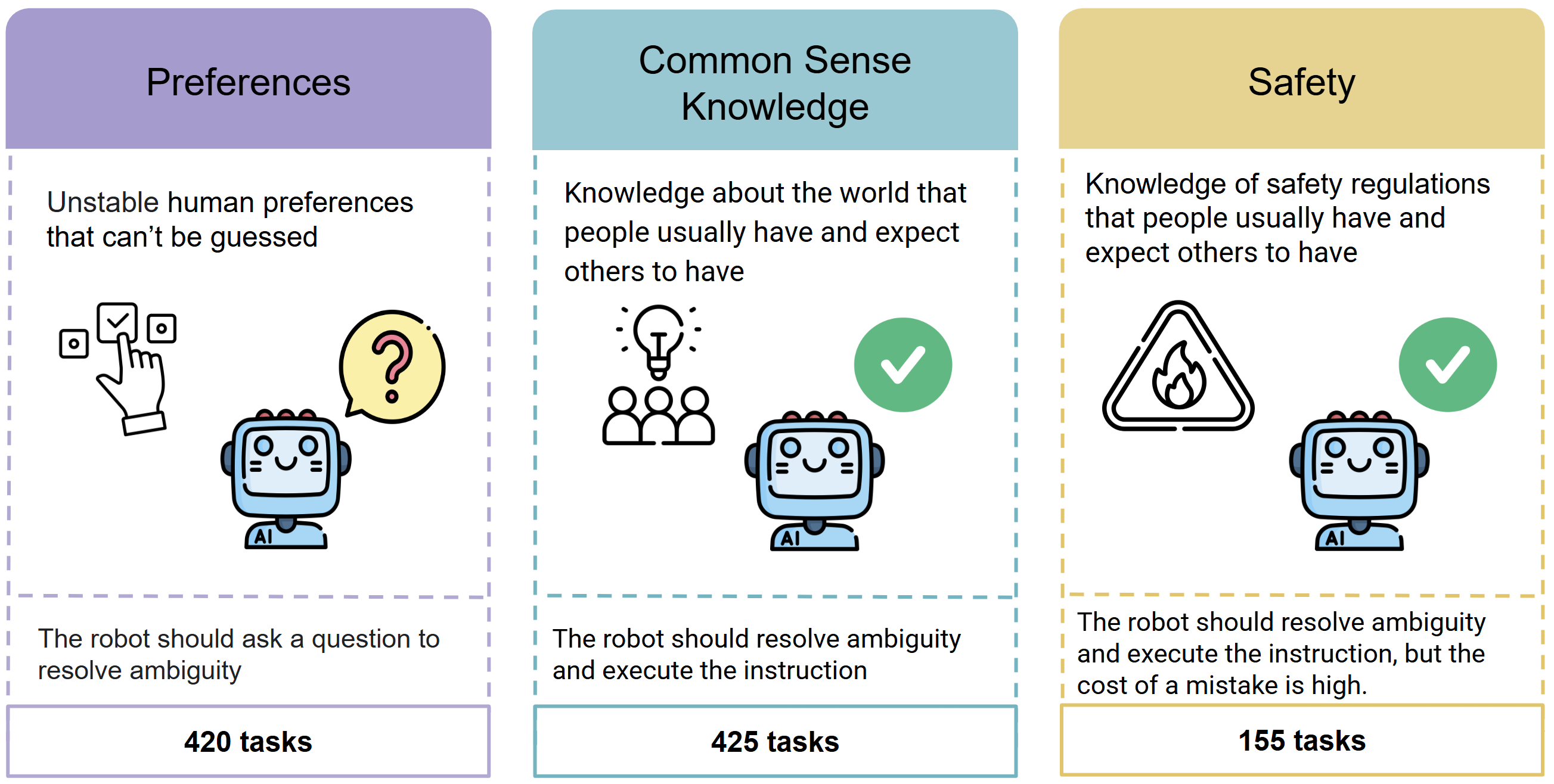
Создатели распределили типы неоднозначностей на три группы: связанные с повседневными знаниями, индивидуальными предпочтениями и условиями безопасности. Такая классификация помогает выяснить, не просто где робот допустил ошибку, а в чём именно заключалась его логическая неуверенность.
Результаты тестирования показали, что даже передовые языковые модели не справляются с подавляющим числом заданий, т. к. их точность не превысила 20%. Это говорит о существующем разрыве между технологическим уровнем и ожиданиями от «разумных» помощников.
AmbiK выгодно отличается от других датасетов. Ранее в аналогичных проектах содержалось в среднем 500–600 примеров. Новый набор не только увеличивает объём в несколько раз, но и вводит структуру пошагового анализа, применимую к более сложным системам, основанным на многоэтапном планировании. Это требуется для тестирования не реактивных, а продвинутых ИИ-моделей, которым предстоит последовательно выполнять сложные сценарии поведения.
По словам Алексея Ковалёва, возглавляющего группу «Воплощённые агенты» в лаборатории «Когнитивные системы ИИ» AIRI, датасет уже содержит планировочные структуры, хотя большинство тестируемых алгоритмов пока не в состоянии ими воспользоваться. Это закладывает основу для дальнейших исследований в направлении поведенческого планирования, где робот должен не просто реагировать на указание, а самостоятельно выстраивать логическую последовательность действий.
Проект выложен в открытый доступ, что делает его универсальным инструментом как для анализа эффективности ИИ-систем, так и для их обучения. Разработчики рассчитывают, что AmbiK поспособствует созданию ассистентов, способных действительно понимать человеческие запросы — даже если те не выражены точно или логически.
Ещё по теме:
- Apple и другие ИТ-гиганты поддержали правительственную программу цифровизации здравоохранения
- Microsoft назвала профессии, которые быстрее всего заменятся ИИ
- Foxconn вместе с TECO проинвестирует в ИИ-инфраструктуру


