
Компания Apple опубликовала свежие данные в своём блоге Machine Learning Research, детально сравнив производительность чипов M5 и M4 при запуске больших языковых моделей (LLM). Тестирование проводилось с использованием фирменного фреймворка MLX, который позволяет запускать алгоритмы машинного обучения нативно на архитектуре Apple Silicon.
Контекст: что такое MLX
Несколько лет назад Apple представила MLX — инструмент, который компания описывает как «массивовый фреймворк для эффективного и гибкого машинного обучения на Apple Silicon».
По сути, это open-source решение, позволяющее разработчикам создавать и запускать модели непосредственно на Mac, используя привычные для ИИ-индустрии интерфейсы. MLX максимально задействует унифицированную архитектуру памяти чипов Apple: операции могут выполняться как на центральном (CPU), так и на графическом процессоре (GPU) без необходимости перемещения данных между ними. API фреймворка напоминает популярную библиотеку NumPy, что упрощает переход для исследователей.
В состав инструментария входит пакет MLX LM, специально предназначенный для генерации текста и дообучения (fine-tuning) языковых моделей. Он поддерживает загрузку большинства популярных моделей с платформы Hugging Face и технологию квантования — метод сжатия, который позволяет запускать большие нейросети с меньшим потреблением памяти и большей скоростью.
В новом отчёте Apple акцентирует внимание на аппаратных улучшениях M5. Ключевую роль в ускорении инференса (процесса работы нейросети) играют новые «нейронные ускорители графического процессора» (GPU Neural Accelerators). По заявлению компании, они обеспечивают выделенные операции матричного умножения, критически важные для задач машинного обучения.
Методология тестирования
Для демонстрации прогресса инженеры сравнили время генерации на MacBook Pro с чипами M4 и M5. Тесты проводились на моделях с открытым кодом:
- Qwen (версии 1.7B и 8B в точности BF16);
- Квантованные до 4 бит версии Qwen 8B и 14B;
- Модели архитектуры «смесь экспертов» (MoE): Qwen 30B (3 млрд активных параметров) и GPT OSS 20B.
Размер входного промпта (запроса) составлял 4096 токенов. Apple замеряла два ключевых показателя: время до появления первого токена и скорость последующей генерации текста.
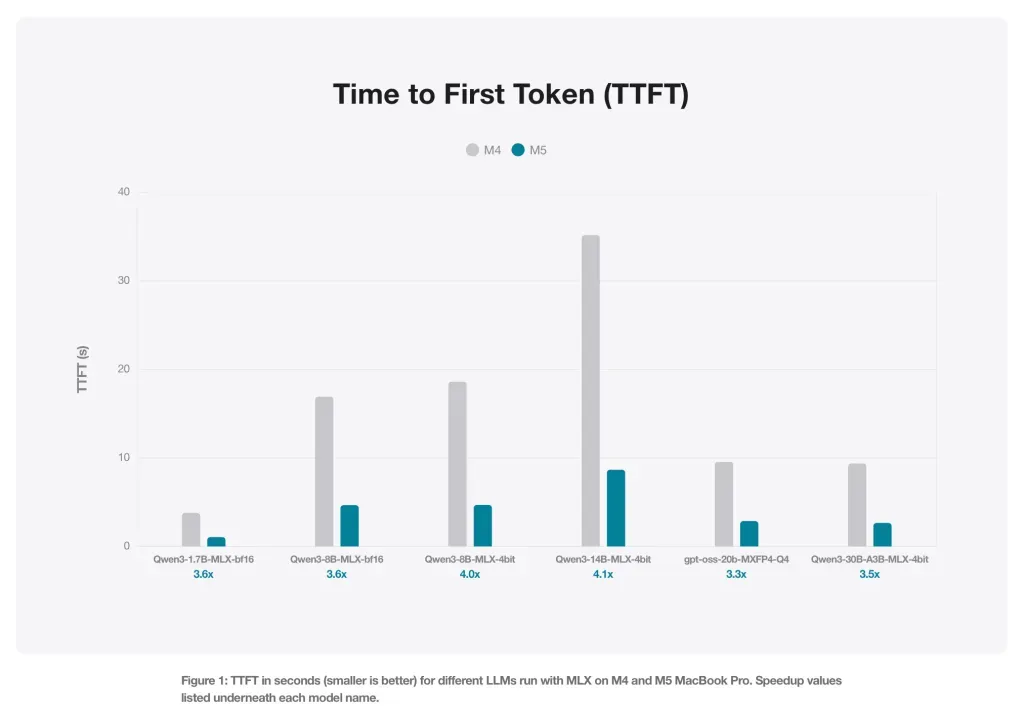
В работе LLM есть важный нюанс: генерация самого первого токена требует огромных вычислительных мощностей (compute-bound), тогда как создание всех последующих токенов упирается в пропускную способность памяти (memory-bound).
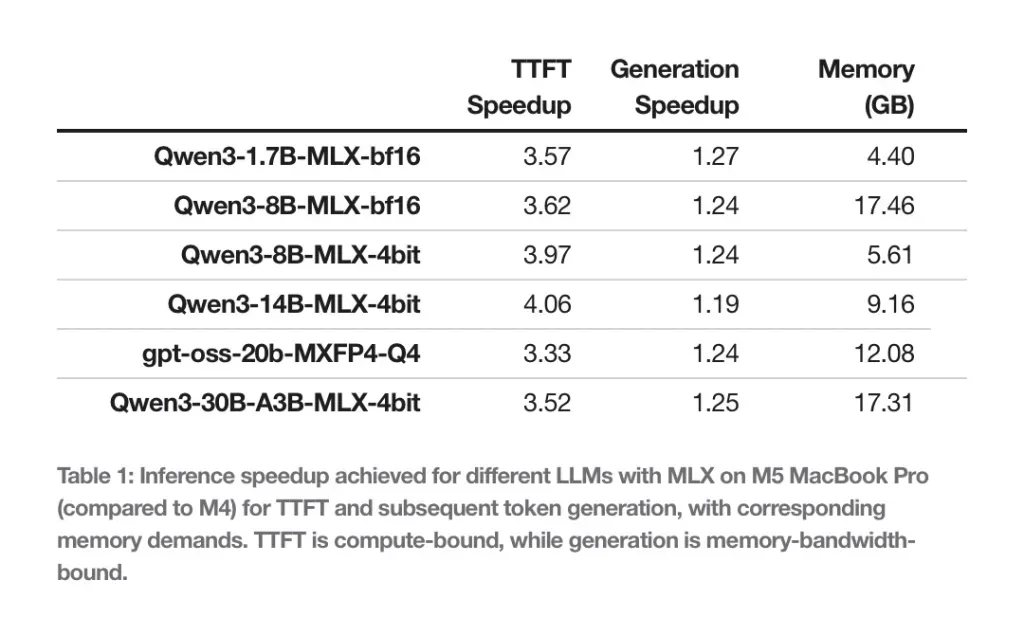
Именно во втором сценарии M5 показал наибольший отрыв. Благодаря увеличенной пропускной способности памяти (153 ГБ/с у M5 против 120 ГБ/с у M4, что на 28% выше), новый чип демонстрирует прирост скорости генерации текста на 19–27%.
Что касается генерации изображений, разрыв оказался ещё более внушительным: M5 справляется с этой задачей более чем в 3,8 раза быстрее, чем предшественник.
Практическое применение
Apple также отметила эффективность использования памяти. MacBook Pro с 24 ГБ оперативной памяти способен без труда разместить в памяти модель Qwen 8B (в формате BF16) или 30-миллиардную MoE-модель (с 4-битным квантованием). В обоих случаях для работы нейросети требуется менее 18 ГБ памяти, что оставляет ресурсы для других задач системы.
Ещё по теме:
- «Семейный план 2» вышел на Apple TV: Марк Уолберг и Мишель Монахэн снова в деле
- Google стирает барьеры: Quick Share на Android стал поддерживать AirDrop
- Apple отменила премьеру сериала «Охота» за несколько дней до релиза


