
В сегодняшней записи в блоге инженеры Apple поделились новыми подробностями о сотрудничестве с NVIDIA, направленном на повышение скорости генерации текста большими языковыми моделями (LLM).
Ранее в этом году Apple опубликовала и открыла исходный код своей методики Recurrent Drafter (ReDrafter). Этот метод обеспечивает новый подход к генерации текста, обеспечивая существенно более высокую скорость и «достигая передовых результатов в отрасли». Он сочетает в себе два подхода: beam search (поиск по нескольким возможным вариантам) и dynamic tree attention (динамическое древовидное внимание) для эффективной обработки разных вариантов.
Несмотря на то, что исследования Apple продемонстрировали впечатляющие результаты, компания пошла дальше и совместно с NVIDIA применила ReDrafter на практике. В рамках этой коллаборации метод ReDrafter был интегрирован в NVIDIA TensorRT-LLM — инструмент, помогающий ускорить работу LLM на графических процессорах NVIDIA.
Чтобы осуществить интеграцию ReDrafter, NVIDIA добавила новые операторы или предоставила доступ к уже имеющимся, что значительно улучшило возможности TensorRT-LLM по работе со сложными моделями и методами декодирования. Разработчики машинного обучения, использующие графические процессоры NVIDIA, теперь могут легко воспользоваться ускоренной генерацией токенов, которую обеспечивает ReDrafter, для производственных LLM-приложений на основе TensorRT-LLM.
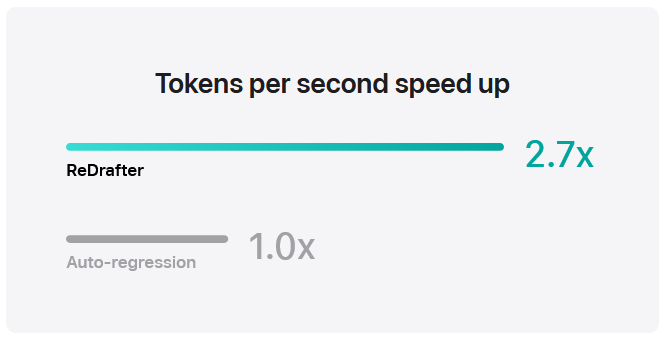
В ходе тестирования производственной модели, состоящей из десятков миллиардов параметров, на графических процессорах NVIDIA с использованием инфраструктуры для ускорения вывода результатов NVIDIA TensorRT-LLM и интеграции ReDrafter, был зафиксирован 2,7-кратный прирост скорости генерации токенов в секунду при использовании жадного декодирования (greedy decoding). Эти результаты показывают, что данная технология может значительно снизить задержки, с которыми сталкиваются пользователи, а также сократить число необходимых графических процессоров и снизить энергопотребление.
«Большие языковые модели всё чаще используются для обслуживания реальных приложений, и повышение эффективности вывода может повлиять на вычислительные затраты и сократить задержки для пользователей», — резюмируют исследователи Apple в области машинного обучения. «Интеграция новаторского подхода ReDrafter к “спекулятивному декодированию” в фреймворк NVIDIA TensorRT-LLM позволит разработчикам получать преимущества ускоренной генерации токенов на графических процессорах NVIDIA для своих производственных LLM-приложений».
Ещё по теме:
- Apple заявляет, что законы ЕС о совместимости создают серьёзные риски для конфиденциальности
- В Роскомнадзоре заявили, что не будут собирать данные пользователей в рамках нового приказа
- Apple сворачивает планы по подписке на iPhone


