
Китайская компания DeepSeek раскрыла данные о стоимости обучения своей модели искусственного интеллекта R1, что стало редким шагом для рынка и вызвало новые вопросы о её возможностях. По заявлению стартапа из Ханчжоу, модель была обучена за $294 000 с использованием 512 графических процессоров Nvidia H800. Эта сумма значительно ниже оценок затрат американских компаний и усиливает подозрения относительно методов работы DeepSeek.
Расчёты приведены в статье в журнале Nature, соавтором которой выступил основатель компании Лян Вэньфэн. Публикация стала первым подробным раскрытием затрат со стороны DeepSeek после её стремительного выхода на международный рынок в январе, когда более дешёвые ИИ-системы компании вызвали падение акций крупных технологических фирм. Для сравнения, глава OpenAI Сэм Альтман ещё в 2023 году заявлял, что обучение базовых моделей обходилось в «намного больше $100 миллионов», хотя точных цифр не называл.
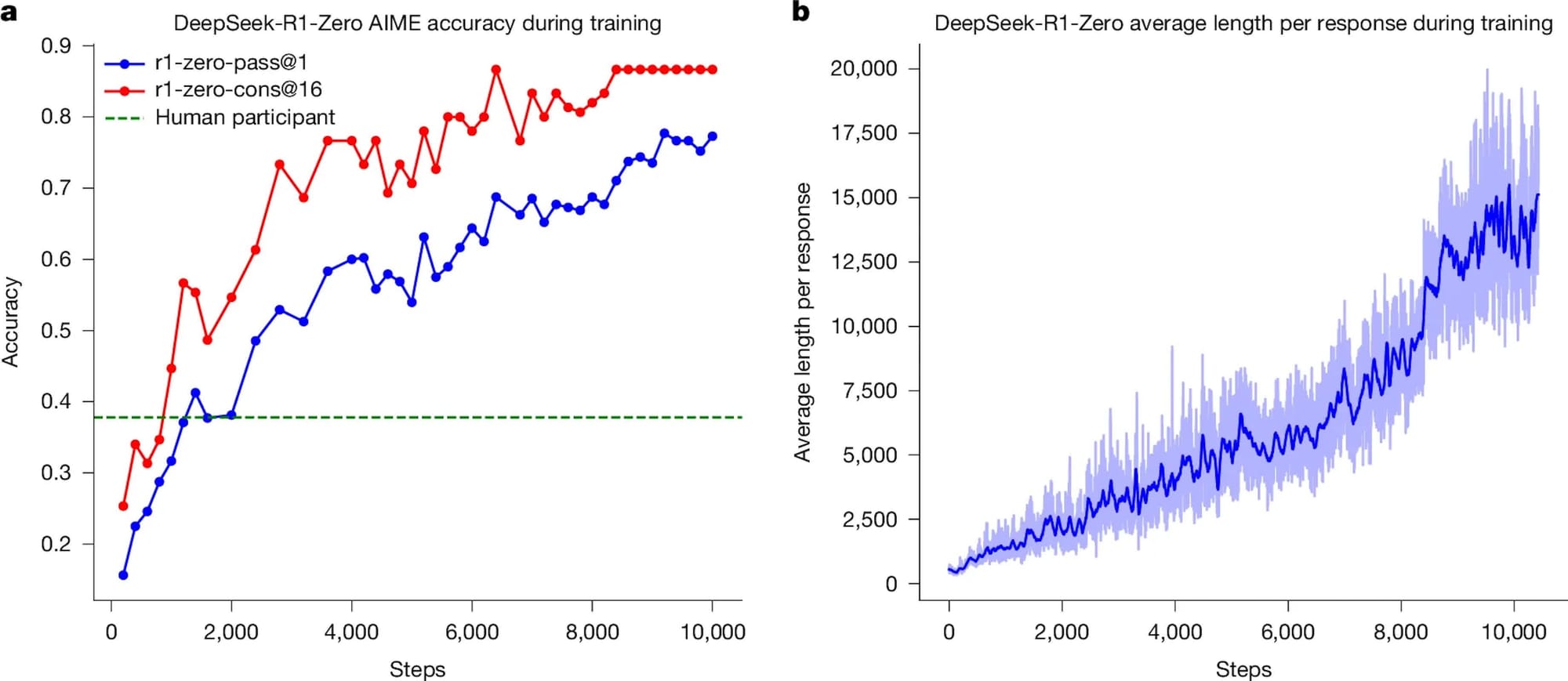
DeepSeek сообщила, что обучение R1 длилось 80 часов на кластере из 512 чипов H800, созданных Nvidia специально для китайского рынка. Дополнительно компания впервые подтвердила владение чипами Nvidia A100, использовавшимися в ранних экспериментах с меньшими моделями. Однако независимые аналитики сомневаются в столь низких расходах. Исследовательская компания SemiAnalysis отмечает, что DeepSeek располагает примерно 50 000 GPU Nvidia Hopper, включая 10 000 H800 и 10 000 H100, а реальные инвестиции составили около $1,6 млрд на серверы, $944 млн на операционные расходы и более $500 млн — на графические процессоры.
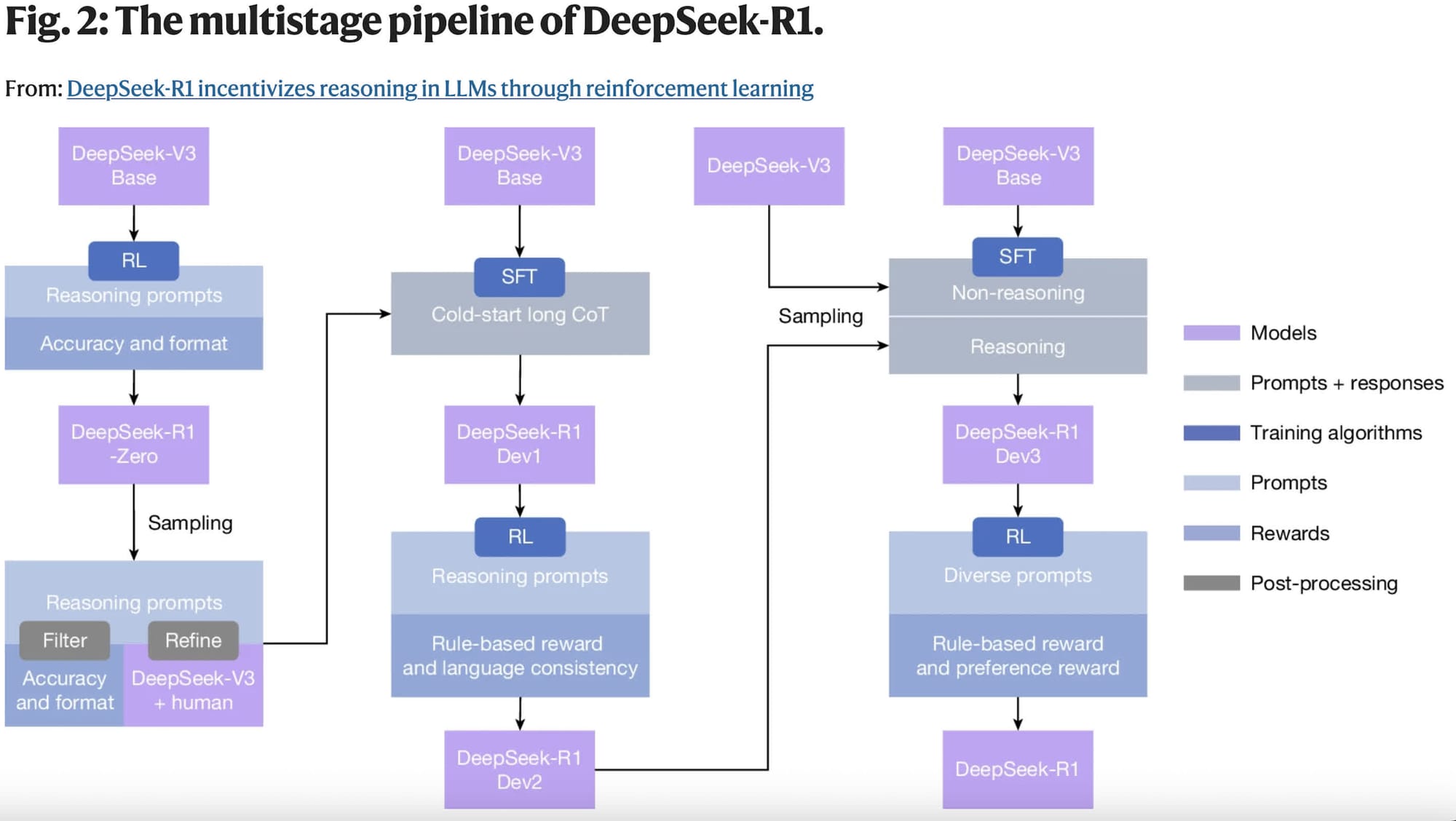
Помимо финансовых вопросов, внимание привлекли методы разработки. Критики, включая американских чиновников и представителей индустрии, утверждают, что компания активно применяет дистилляцию — обучение моделей на выводах других систем. DeepSeek настаивает, что этот подход позволяет создавать более доступные решения, пригодные для масштабного внедрения. В публикации также признано, что в датасете для модели V3 использовалось «значительное количество» ответов, сгенерированных системами OpenAI. Компания утверждает, что это было следствием сбора данных из открытых источников, а не преднамеренным копированием.
Таким образом, раскрытие стоимости и методов работы лишь усилило споры о реальных масштабах и возможностях DeepSeek. Несмотря на низкий публичный профиль, стартап продолжает развивать продукты и позиционирует себя как альтернативу американским конкурентам, где затраты на обучение моделей только стремительно растут.
Ещё по теме:
- Apple пожертвовала SIM-лотком ради большей батареи
- iPhone 17 Pro Max сохранил модем от Qualcomm
- JerryRigEverything доказал несгибаемость iPhone Air


