
Капча — это способ защиты сайтов от ботов, которые могут заниматься спамом, взломом или другими нежелательными действиями. Капча предлагает пользователю ввести текст или выбрать изображения, которые трудно распознать для машин. Но насколько эффективна эта защита в эпоху развития искусственного интеллекта?
Недавно стало известно, что исследователи из Google Research разработали модель Pix2Struct, которая может точно распознавать размытый текст на капче-картинке. Модель обучалась на скриншотах веб-страниц с простым HTML-кодом и умеет восстанавливать текст по его частичному скрытию. Таким образом, Pix2Struct может легко пройти капчу с текстом.
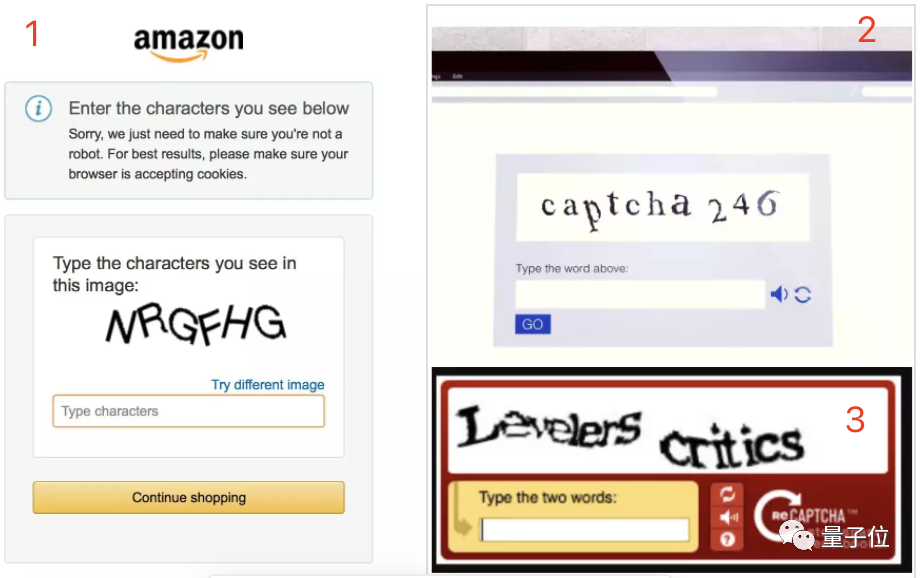
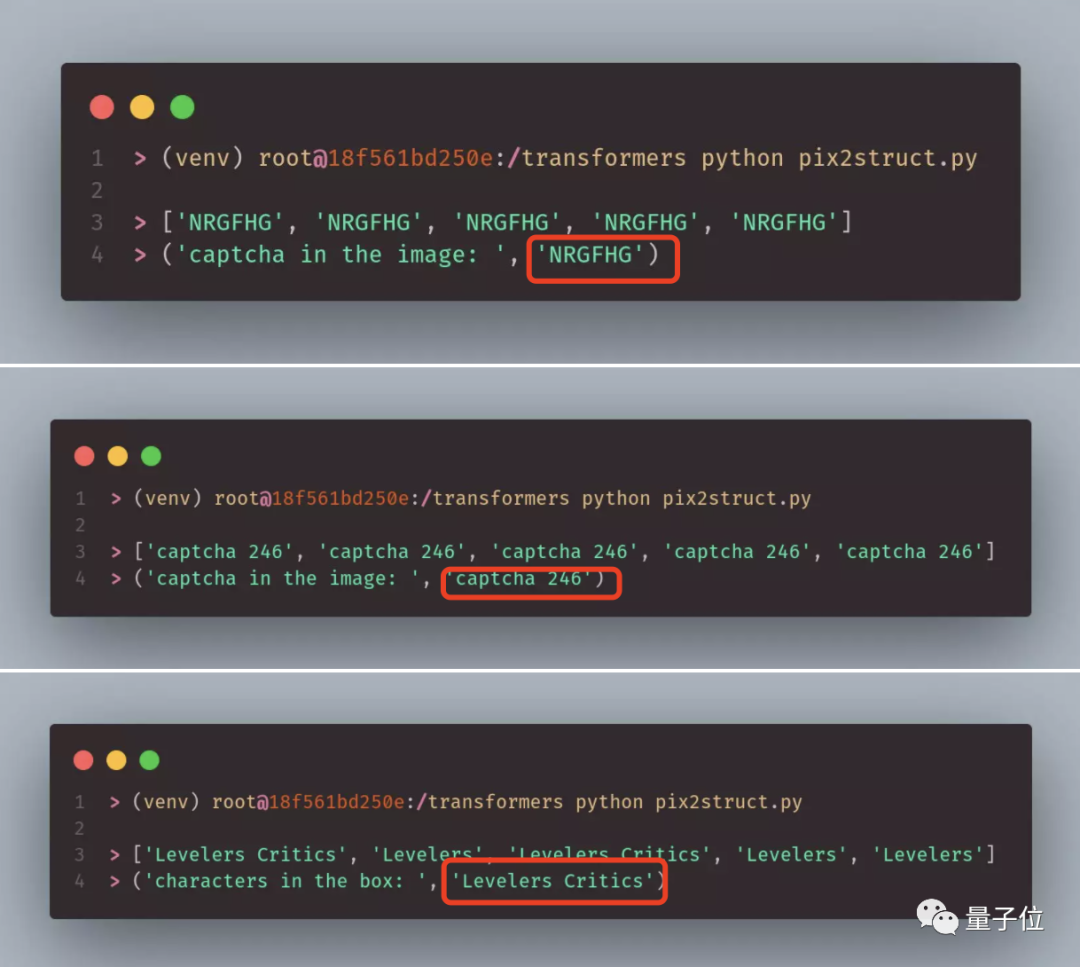
По словам разработчиков, Pix2Struct — это предварительная модель ИИ для преобразования изображения в текст. Для того чтобы «увидть» текст на картинке нейронная сеть анализирует HTML-код. Она способна изучать базовую структуру любой страницы, в независимости от того, какие элементы использовались для её создания.
Этот случай показывает, что современные технологии искусственного интеллекта способны обманывать или обходить капчу, которая раньше считалась надёжным способом защиты от ботов. Это может представлять угрозу для безопасности и конфиденциальности данных пользователей и сайтов. С другой стороны, это также свидетельствует о прогрессе в области компьютерного зрения и естественного языка, которые могут быть полезны для многих других задач и приложений.
Возможно, в будущем потребуется разработать более сложные и умные способы проверки подлинности пользователей в интернете.
Ещё по теме:
- Глава Apple Тим Кук обсудит ситуацию в Китае с американскими законодателями
- Amazon грозит иск за незаконный сбор данных о детях
- Spotify отказывается от нативной поддержки HomePod, но снова обещает добавить AirPlay 2


