
Компания DeepSeek объявила о выходе предварительной версии своей новой языковой модели — DeepSeek V4. Разработка традиционно распространяется с открытыми весами, что делает её одним из самых мощных общедоступных решений на рынке. Главной технологической особенностью релиза стала поддержка огромного контекстного окна объёмом до 1 миллиона токенов.
Разработчики представили нейросеть в двух конфигурациях: флагманской Pro и облегчённой Flash. Версия DeepSeek V4 Pro позиционируется как тяжеловесное решение для сложных вычислительных задач. Её архитектура включает 1,6 триллиона общих параметров, из которых 49 миллиардов активируются при каждом запросе. В свою очередь, версия Flash создана для более массовых задач – она насчитывает 284 миллиарда общих и 13 миллиардов активных параметров.
Как утверждают в компании, версия Pro демонстрирует уровень логических рассуждений, недоступный ранее для открытых моделей, и обладает широкой базой знаний о мире. По своим агентным возможностям – способности ИИ самостоятельно планировать и выполнять многоступенчатые задачи — новинка вплотную приблизилась к закрытым коммерческим флагманам вроде Gemini 3.1 Pro. Особенно разработчики выделяют компетенции DeepSeek V4 в математике, программировании и дисциплинах STEM (наука, технологии, инженерия, математика), где алгоритм на данный момент обходит все существующие открытые аналоги.
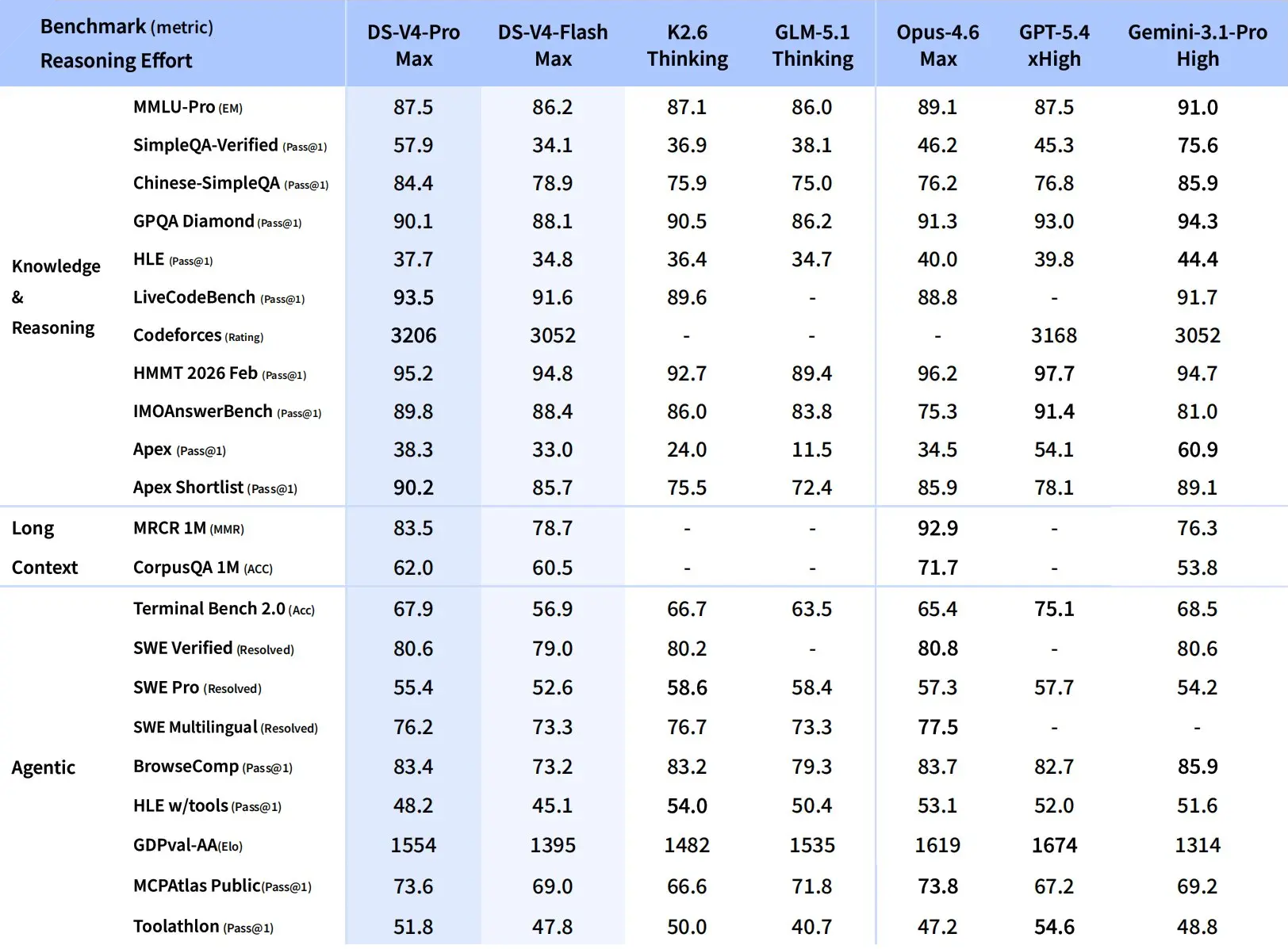
Облегчённая модель Flash, несмотря на более скромные габариты, сохраняет сопоставимый с Pro-версией уровень логики, особенно когда речь идёт о базовых агентных сценариях. Её главное преимущество заключается в экономичности и эффективности вычислений.
Опробовать обе модели уже можно на официальном сайте DeepSeek в двух форматах: базовом Instant Mode и продвинутом Expert Mode. Для сторонних разработчиков также открыто тестирование через обновлённый API.
Компания делает акцент на агрессивной снижении стоимости использования своих нейросетей. Тарификация напрямую зависит от того, попадает ли запрос в кэш (cache hit) или обрабатывается с нуля (cache miss), что позволяет существенно экономить на повторяющихся задачах.
Стоимость использования DeepSeek V4 Flash:
- Обработка входящих токенов: от $0,028 (или $0,14 без кэширования);
- Генерация исходящих токенов: $0,28.
Стоимость использования DeepSeek V4 Pro:
- Обработка входящих токенов: $0,145 при обращении к кэшу и $1,74 при его отсутствии;
- Генерация исходящих токенов: $3,48.


