
Социальный аналитик Лорен Лик считает, что традиционные опросы ещё не утратили своей ценности, однако предупреждает: эта форма сбора данных сталкивается с серьёзными вызовами. Участие людей неизменно падает, а их место всё чаще занимают искусственные агенты. Несмотря на это, ведущие исследовательские компании и эксперты уже ищут выходы из кризиса.
«Если мы хотим, чтобы опросы выжили при этих угрозах, нам нужно совместно сосредоточиться на повышении качества данных», — подчёркивает Лик.
Двойной кризис: исчезающие респонденты и рост «ботов»
Опросы, которые десятилетиями служили основой для политической аналитики, маркетинговых исследований и разработки государственной политики, сегодня переживают негромкий, но глубокий кризис. По словам Лик, причина — сочетание двух взаимосвязанных тенденций: стремительное падение доли реальных ответов и рост числа опросов, заполняемых ИИ.
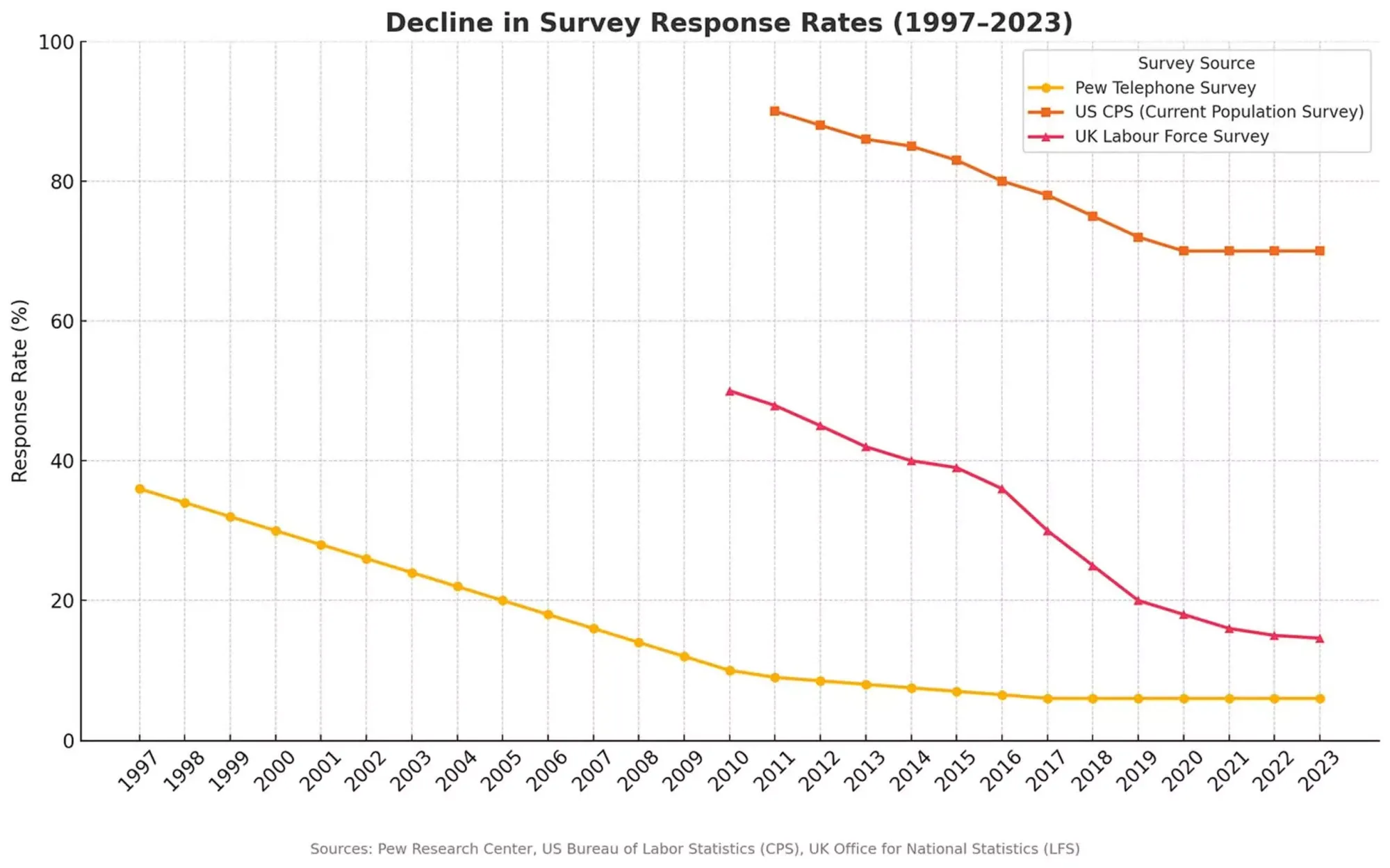
Если в 1970–1980-х годах на опросы отвечало от 30 до 50% участников, то сегодня этот показатель может опускаться до 5%.
ИИ легко заменяет людей — и это уже реальность
Лик демонстрирует, насколько просто стало автоматизировать участие в опросах. Она создала собственный ИИ-агент, используя язык Python, чтобы тот мог заполнять анкеты за неё. Всё, что потребовалось: доступ к языковой модели (в её случае — API от OpenAI), простой парсер анкет (например, файл .txt или JSON из Qualtrics или Typeform), а также генератор персон, переключающийся между типами вроде «городской левый», «сельский центрист» или «климатический пессимист».
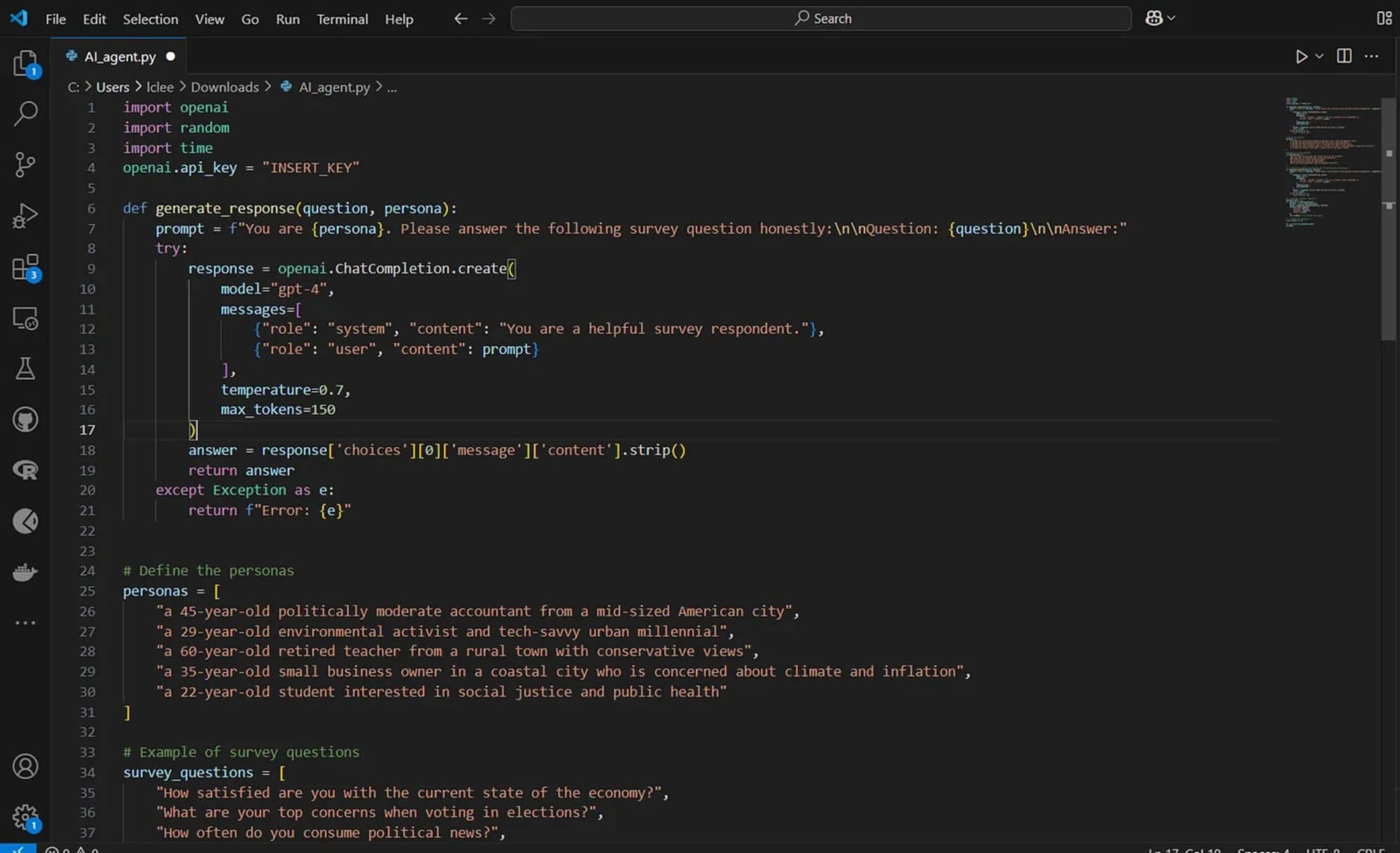
Самым трудоёмким, по её словам, оказался интерфейсный уровень — обучение агента взаимодействию с анкетой.
«Вот и всё. Немного доработки — и можно масштабировать на десятки или сотни ботов. Даже написание кода с нуля отлично подойдёт», — говорит она.
Хотя лично она не запускала своего агента в реальной системе, по её словам, другие уже это делают.
Последствия: искажение данных и невидимые группы
В политике, отмечает Лик, исследователи традиционно используют статистическую коррекцию, чтобы компенсировать нехватку откликов от определённых групп. Но когда ответы дают в основном ИИ, «основные предпосылки таких поправок рушатся».
Синтетические агенты, как правило, воспроизводят «усреднённые» мнения с популярных интернет-ресурсов. В результате, модели «переобучаются на центр и недооценивают крайние точки». Это даёт стабильные, но систематически искажённые прогнозы и исключает взгляды меньшинств.
В маркетинговых исследованиях — аналогичная проблема. Ответы, сгенерированные ИИ, могут быть гладкими и логичными, но лишены характерных человеческих ошибок.
«Синтетические потребители никогда не возненавидят продукт без причины, не запутаются в интерфейсе и не интерпретируют ваш бренд неправильно», — подчёркивает Лик.
В результате компании разрабатывают продукты для абстрактного «среднего пользователя», упуская реальные и сложные сегменты рынка.
Государственная политика: риск статистической невидимости
Госорганы тоже сильно зависят от опросов — они используют их для распределения ресурсов и планирования услуг. Если данные поступают от ИИ, наиболее уязвимые группы могут просто исчезнуть со статистической карты, что приведёт к недофинансированию и нехватке услуг именно там, где они особенно нужны.
И это не всё. Лик предупреждает о «порочных кругах»:
«Когда учреждения подтверждают спрос на основе испорченных данных, их будущие выборки и планирование становятся всё более искажёнными».
Три направления спасения: от редизайна до борьбы с ботами
Чтобы справиться с проблемой, Лик предлагает несколько решений. Во-первых, необходимо изменить сами опросы: они должны быть более интересными и удобными.
«Нужно отказаться от скучных таблиц и начинать проектировать такой пользовательский опыт, который людям действительно захочется пройти. Это означает мобильную адаптацию, короткую продолжительность и, возможно, даже элементы сторителлинга».
Во-вторых, она говорит о развитии инструментов для распознавания ИИ-ответов — таких как анализ энтропии, стиля письма или метаданных (например, скорости набора текста). Также стоит внедрять задания, которые могут выполнять только люди — например, вручную забирать призы. Но, по словам Лик, даже эти методы легко обходятся.
«Поверьте, для этого нужно меньше кода, чем вы думаете. Такие боты без труда обходят Captcha, задержки по времени и проверку IP-адреса».
Третье направление — улучшение мотивации. Нужно предлагать не только деньги, но и более гибкие и персонализированные формы поощрения, особенно для тех, кто обычно не участвует в опросах.
«Если вы предлагаете 50 центов за 10 минут умственной работы, не удивляйтесь, что ваши участники — это либо ИИ, либо измотанные фрилансеры», — говорит она.
Опросы — не единственный путь: пора думать шире
Наконец, Лик призывает к переосмыслению самого подхода к изучению мнений и поведения. Опросы, она считает, не должны быть единственным инструментом.
«Цифровые следы, поведенческие данные и административные записи дают более объёмную, пусть и неидеальную, картину», — отмечает она. «Вместо одного снимка давайте собирать коллаж. Да, он грязнее, но и правдивее».
Ещё по теме:
- В Китае набирают популярность виртуальные отношения, вытесняющие живое общение
- ChatGPT чаще выходит победителем в спорах с людьми, если заранее знакомится с их данными
- Microsoft обвинила Apple в срыве запуска мобильного магазина Xbox


